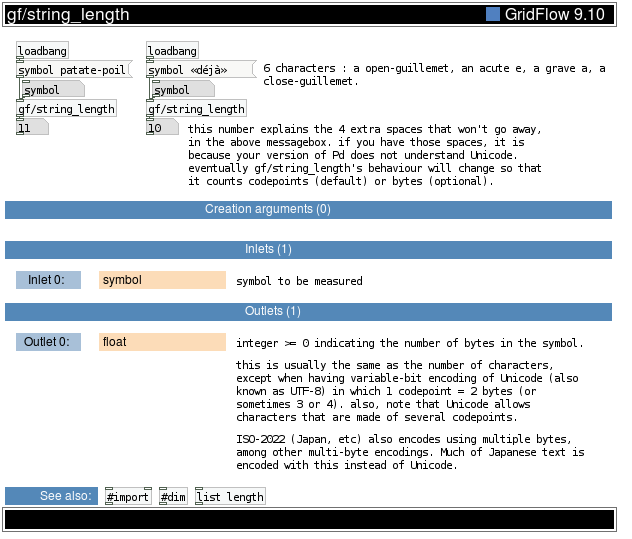
integer >= 0 indicating the number of bytes in the symbol. symbol to be measured ISO-2022 (Japan, etc) also encodes using multiple bytes, among other multi-byte encodings. Much of Japanese text is encoded with this instead of Unicode. this number explains the 4 extra spaces that won't go away, in the above messagebox. if you have those spaces, it is because your version of Pd does not understand Unicode. eventually gf/string_length's behaviour will change so that it counts codepoints (default) or bytes (optional). this is usually the same as the number of characters, except when having variable-bit encoding of Unicode (also known as UTF-8) in which 1 codepoint = 2 bytes (or sometimes 3 or 4). also, note that Unicode allows characters that are made of several codepoints. 6 characters : a open-guillemet, an acute e, a grave a, a close-guillemet.